Table of contents
Open Table of contents
Gemini Pro vs Advanced vs Ultra
I find Google’s naming of things to be very confusing. They’ve recently rebranded their LLM from Bard to Gemini and introduced different names to correspond to different model sizes. In Gemini 1.0 they’ve got Ultra, Pro, and Nano:
- Gemini Ultra — our largest and most capable model for highly complex tasks.
- Gemini Pro — our best model for scaling across a wide range of tasks.
- Gemini Nano — our most efficient model for on-device tasks.
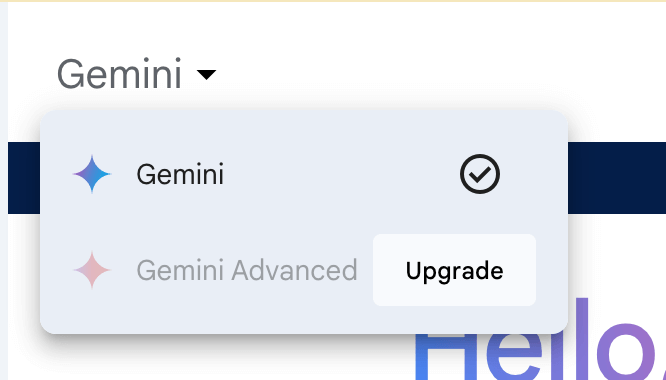
Gemini Advanced is the paid version that gives you access to the Ultra model
There was mention of Gemini Advanced in the announcement, but kept seeing it in articles without mention of what it actually was., turns out Advanced is the paid version of Gemini. It was described the in a Gemini Ultra blog post. By paying for Gemini Advanced, you’ll get access to the Gemini Ultra model. It is a feature that you subscribe to using the Google One AI premium plan, which costs $20/month.
Or you can click on the drop down menu when you log into Gemini. The free version of Gemini gets you the Pro model. Since it’s not labeled in the interface it’s mad confusing.
Gemini Advanced is akin to ChatGPT Plus which also costs $20/month. GPT Plus gives you access to the more advanced GPT-4 (which includes image creation), while only GPT-3.5 is available to free users.
Accessing the new 1.5 version of Gemini
To get access to this new model, you’ll need to use it through Google AI studio. Signing up now will get you access to Gemini 1.0, you can sign up to their wait list for 1.5. It took me about two weeks to be taken off the wait list.
In the Gemini 1.5 version announcement, you’ll get a 1 million token context window.
In comparison to current models, Google’s language model has experienced a significant increase in context window. GPT-4 Turbo and Claude 2.1 have context windows of 128,000 and 200,000 tokens, respectively. However, Google’s model boasts a context window of 1 million tokens, and in research settings, it can reach up to 10 million tokens.
A Massive Leap in Context: What 10x Bigger Means for Language Models
Imagine the possibilities when a language model can access and process information ten times more than before. With Google’s new model boasting a context window of 1 million tokens (and even 10 million in research settings), we’re entering a new era of possibilities:
-
Analyze entire codebases: Throw in code and get back analysis, test generation, or even API documentation.
-
Consume content instantly: “Read” a novel or “watch” a movie in seconds and receive detailed summaries.
-
Find hidden patterns: Filter massive datasets like server logs or financial data to identify patterns and outliers.
-
Develop a “short-term memory”: Overcome the forgetfulness of current models and build LLMs that can remember past conversations, mimicking human memory.
This advancement renders many existing RAG (Retrieval-Augmented Generation) tools less valuable. While RAG was useful for breaking down large datasets and providing relevant chunks to LLMs for context, larger context windows eliminate the need for such techniques in many cases.
However, RAG remains relevant for specific applications like searching vast academic databases or building AI-powered search engines. For most consumer-facing applications, a million-token context window with high retrieval accuracy will likely offer a superior solution.
This leap in context window size signifies a significant step towards more human-like interactions with LLMs, paving the way for a future where these models can remember who we are and what we’ve discussed, leading to more natural and engaging conversations.