Scraping websites with LLMs and AI
This blog was originally about making AI images, but ended up straying a bit and haven’t been coding much lately. Finally decided to work on some new side projects to get my income up as this job market is still unstable. One project I’ve been thinking of involves scraping some data on one site to compare it with data on another, so I started looking at how to crawl and scrape a site.
I remember using Nightmare.js back in the day, but that’s been long dead. A quick Google shows tutorials on things like cheerios, Beautiful Soup, and Puppeteer/Playwright That all seemed like a bit of a drag, I’m too lazy for all that querySelector() and such. Luckily I stumbled upon a video by “LLMs for Devs”:
In it he mentions a few tools:
Knowing those tools got me to digging around a bit more and found some other possible solutions:
I started with Jina AI, but the landing page was confusing so I moved on to Firecrawl. It’s docs had everything I needed and so I didn’t really explore the rest of the options listed above.
Experimenting with Firecrawl
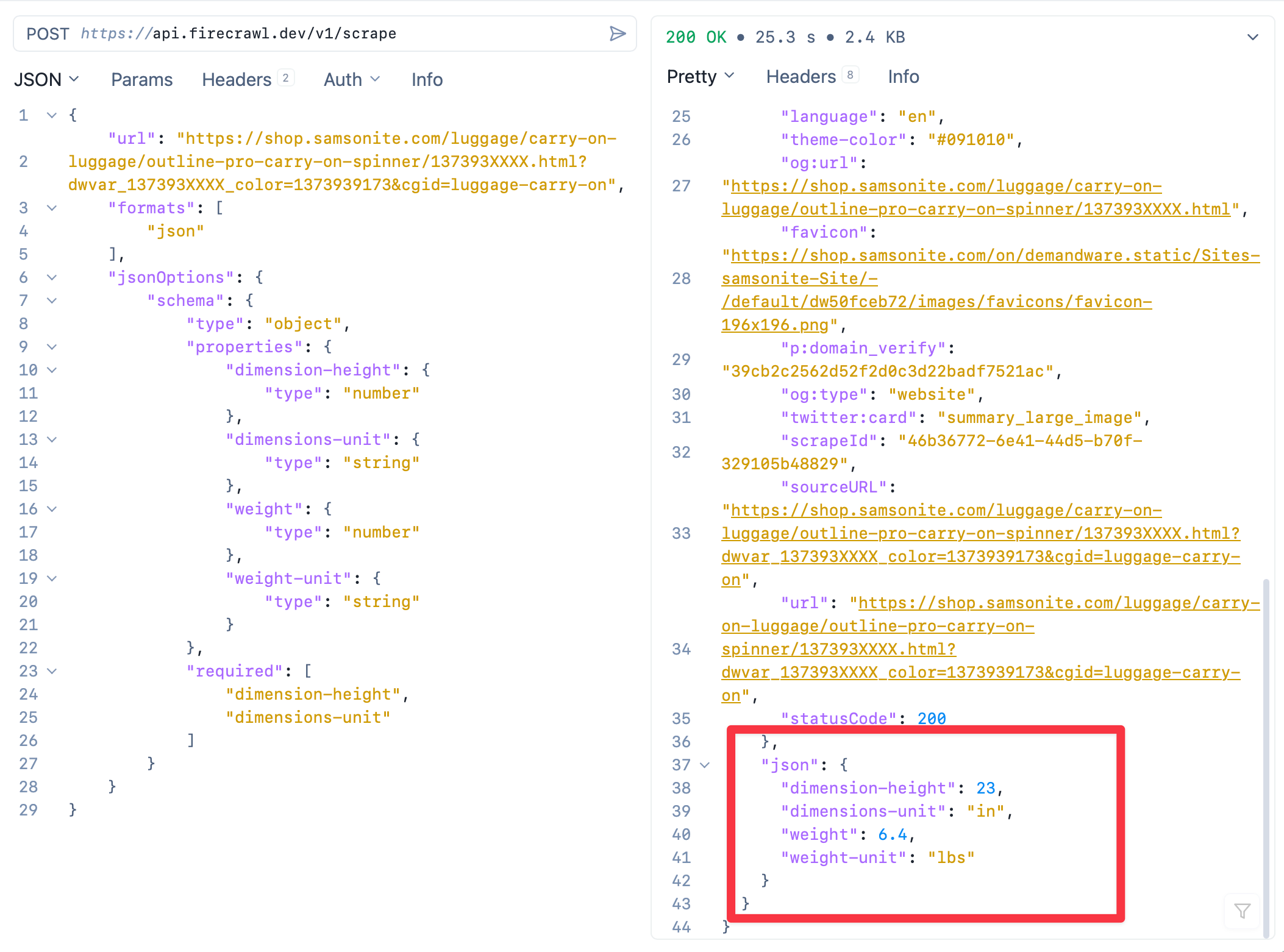
After signing up and getting my API key from Firecrawl, I fired up Yaak and pasted in the example curl command for the /scrape end point where the output include extracted data.
I created the schema of what I wanted returned. In this case, I wanted to know the height and weight of some Samsonite luggage.
The body of the JSON is below:
{
"url": "https://shop.samsonite.com/luggage/carry-on-luggage/outline-pro-carry-on-spinner/137393XXXX.html?dwvar_137393XXXX_color=1373939173&cgid=luggage-carry-on",
"formats": ["json"],
"jsonOptions": {
"schema": {
"type": "object",
"properties": {
"dimension-height": {
"type": "number"
},
"dimensions-unit": {
"type": "string"
},
"weight": {
"type": "number"
},
"weight-unit": {
"type": "string"
}
},
"required": ["dimension-height", "dimensions-unit"]
}
}
}I used keys that described the data I wanted on the page, such as the height of the luggage, and the unit used in that height.
The output is in the below screenshot. The endpoint returned a lot of standard site info, and the requested data in a JSON object.
That was easy.
No digging through HTML, trying to match patterns of where the data might be. Holy crap, this will speed up development greatly. Really reduces all the tedious parts of scraping.
Next step is to see how well the crawling works. Pretty excited about the potential of how much time this will save. Will probably look at the open source options as well. Might need to scrape some sites that need logins.